
I bumped into this Video below explaining the process, thought it was some food for thought.
I ran Inmoovs hand through Google's Deep Dream ( one source http://psychic-vr-lab.com )
Original image 1st Iteration
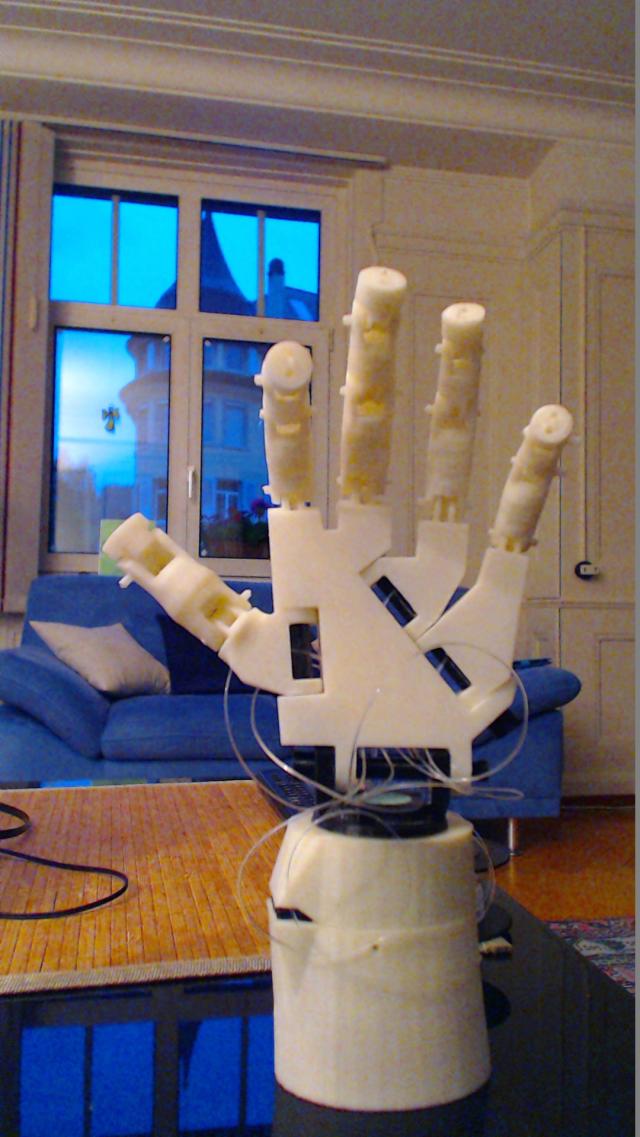

What the heck does it see what I cant see, yikes spooky......
(just noticed the glass angel in the window turns into a hybrid Cat/Cow combo)...
Interestingly it sharpens and also refreshes the content, keeping the image alive:-
2nd Iteration 3rd Iteration

Things to note :-
Each Iteration is regenerating the scene (its sharper, encouragingly without the normal artifacts that a sharpen image filter would do).
The angel is looking a bit more angelic..
There is the starting of a man holding the wrist part and what looks like controlling the wrist joint with head acting as ring/pinky finger flex point.
Thumb dog is getting quite furry now.
Some blue robot characters are appearing bottom left.
One sinister character hides directly behind the wrist and another appears in the gap at base of thumb.
There is a monkey type character developing on the far left of the couch as we look at it..... it frightens to look closer.
There is a lot of speculation in the reading of this particular picture, however bear in mind the Google Deep Dream is biased to find people,eyes,animals and buildings (sinister!!) , so to train it to find other things then these other things must be placed in the deep learning matrix, so us MRL's need more plugs,sockets,connector,walls,tables,chairs,stairs,ball and hand-tool speculation matrix's
N.B.1 :- could it be used for paranormal activity, i.e. sped up to real time, to reveal the ghosts and demons that are sitting right now next to us, the very ones that release the blue smoke and add syntax-error code .
N.B.2 :- analyse "Before and After" disaster/crime scenes and see where the weak spots might show some light on the scene (i.e.911,Chernobyl,Fukushima)
What are the inputs ? The way
What are the inputs ?
The way I understand it - it has previous training .. or at the minimum previous input.
Otherwise it could not fathom an eye nor what something 'looks' like an eye ..
So are all these already part of the 'learned' dream ?
Very stimulating post Gareth .. always a pleasure :D
Caffe and IPython,NumPy,SciPy,Anaconda,Canopy
Two links :-
https://research.googleblog.com/2015/07/deepdream-code-example-for-visualizing.html
and
http://caffe.berkeleyvision.org/ Deep learning framework
Quote :- "Once you’re set up, you can supply an image and choose which layers in the network to enhance, how many iterations to apply and how far to zoom in. Alternatively, different pre-trained networks can be plugged in."
I have not tried to get these working yet, I looks like you can get more control over the different nodes/layers this way.... so far all the online generators I have found have very little control over the parameters.
Inputs
Two inputs. The image that you upload and a network that is trained to detect cats. So it tries to find cats. And then the areas where it finds bit's of cat are backpropagated to show "more cat". I think it takes bits and pieces from the training set and replaces parts of the image with parts from the training images set.
So to get something completley different you need some other network that is trained to detect something else, like buildings. Then your picture would be changed to look more like a building. And this can be done at different levels in the network.
Right, I was wondering if the
Right,
I was wondering if the original set of images which trained the network was available...
More cat & More cow bell ! :)