AbstractSpeechSynthesis
Inspired from moz4rs initial work here.
Abstract classes are great ! They implement the interfaces we want, and additionally implement common methods. This is fantastic, because it reduces code. And less code means less bugs.
Welcome AbstractSpeechSynthesis.
.png)
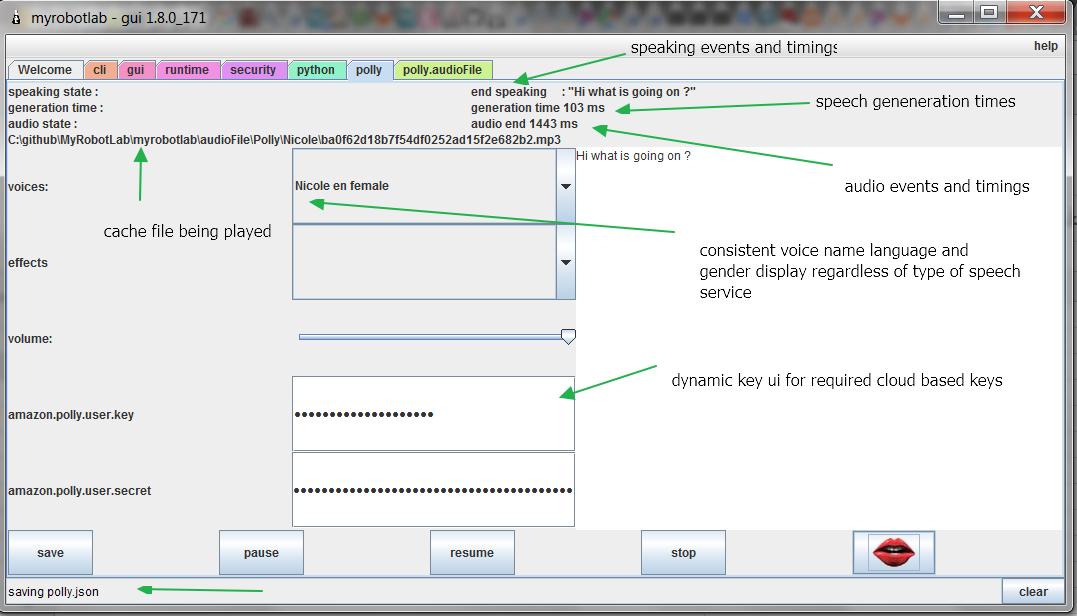
All our SpeechSynthesis services now derive from this single class. Most of the SpeechSynthesis' data & methods will come from AbstractSpeechSynthesis. This makes AbstractSpeechSynthesis super powerful. When you fix any part of AbstractSpeechSynthesis you fix all 7+ of the derived services. Conversly, it also means if you give the AbstractSpeechSynthesis a bug .. you give it to all 7+ derived services.
It also becomes much easier to implement a new SpeechSynthesis service. To create a new SpeechSynthesis service, you only need to implement 2 methods, loadVoices & generateAudioData. The signatures are below.
loadVoices()
generateAudioData(AudioData audioData, String toSpeak)
loadVoices is a method which gets called when the service starts. And the service uses another method to load a voice - welcome the addVoice method :
addVoice(String name, String gender, String lang, Object voiceProvider)
e.g.
addVoice("Mary", "female", "en-GB", "Mary")
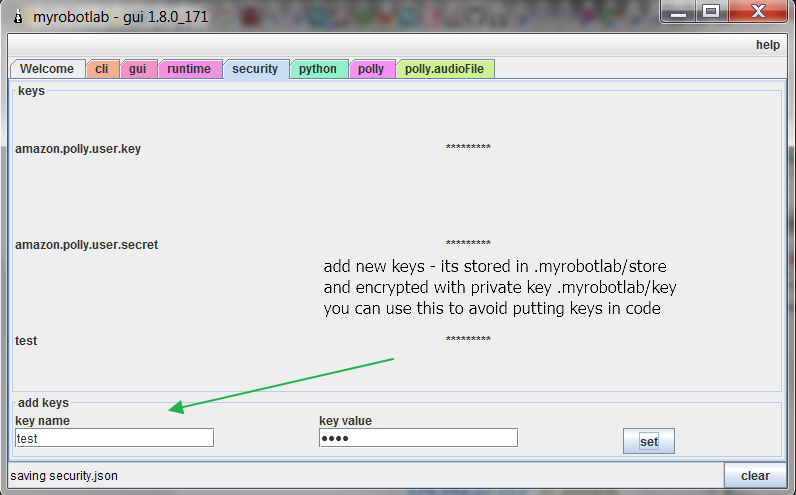
The voiceProvider is a key into the implementation which will provide the voice. In most cases its just a String value of the name.
Here is an example in MarySpeech
addVoice("Spike", "male", "en-GB", "dfki-spike-hsmm")
In this case the MarySpeech code needs a mapping to a "friendly" name to a key name which the implementation understands.
SSML and VoiceEffects
SSML (Speech Synthesis Mark Up) is a way to specify prosody and audio details when synthesizing speech. It potentially allows pitch, contour, pitch range, rate, duration, volume, and other details to be specified in the text sent to the Speech Synthesis service.
VoiceEffects is something moz4r implemented. Originally it came from AcapelaSpeech. A simple way of adding sounds such as laughing, crying, coughing, or any sound file to your speech.
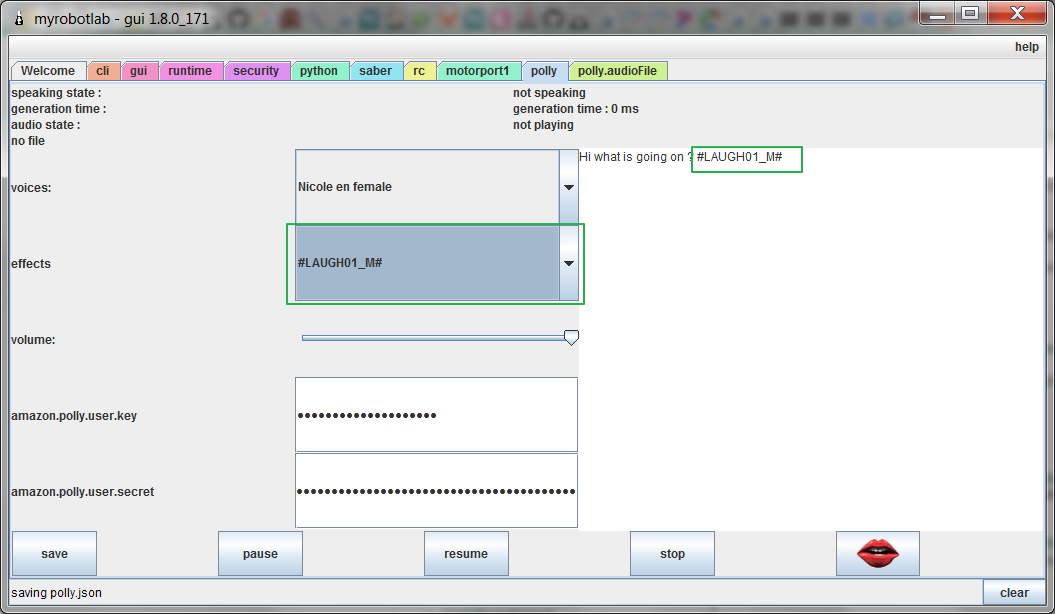
The effects are files put into audioFile/voiceEffects (must be mp3s).
Wahoooo, Grog, it shines .
Wahoooo, Grog, it shines . will play with all of this